Analysing email sentiment

Using Python to analyse languge sentiment of job application responses.
Kaggle user 'sethpoly' was, once upon a time, applying to a lot of a jobs and wanted to build in automation to help with this applications. Of course, as the best of us know, job hunting comes with a lot of rejection emails, so he created a dataset to filter rejection and non/rejection emails. This task was to see what insights could be gained from analysing the text of these emails.
To start: using WordCloud to visualise the most commonly occurring words in both types of email.
First the reject emails:
And then the non-rejection emails:

And also creating them in list form:
Top 20 Most Common Words in 'reject' Emails:
[('interest', 81), ('thank', 68), ('position', 68), ('time', 57), ('unfortunately', 53), ('software', 47), ('move', 44), ('application', 41), ('apply', 36), ('forward', 34), ('opportunity', 32), ('engineer', 31), ('best', 31), ('team', 29), ('job', 29), ('career', 29), ('appreciate', 28), ('wish', 27), ('candidate', 26), ('role', 25)]
Top 20 Most Common Words in 'not_reject' Emails:
[('software', 44), ('job', 35), ('application', 32), ('engineer', 32), ('please', 31), ('resume', 30), ('team', 26), ('thank', 26), ('review', 23), ('experience', 23), ('get', 22), ('work', 21), ('email', 21), ('u', 21), ('position', 21), ('account', 20), ('developer', 19), ('new', 19), ('receive', 18), ('detective', 18)]
But this doesn't really tell us much that is hugely groundbreaking, right? So the next step was to put these words into bigrams and trigrams, for example...
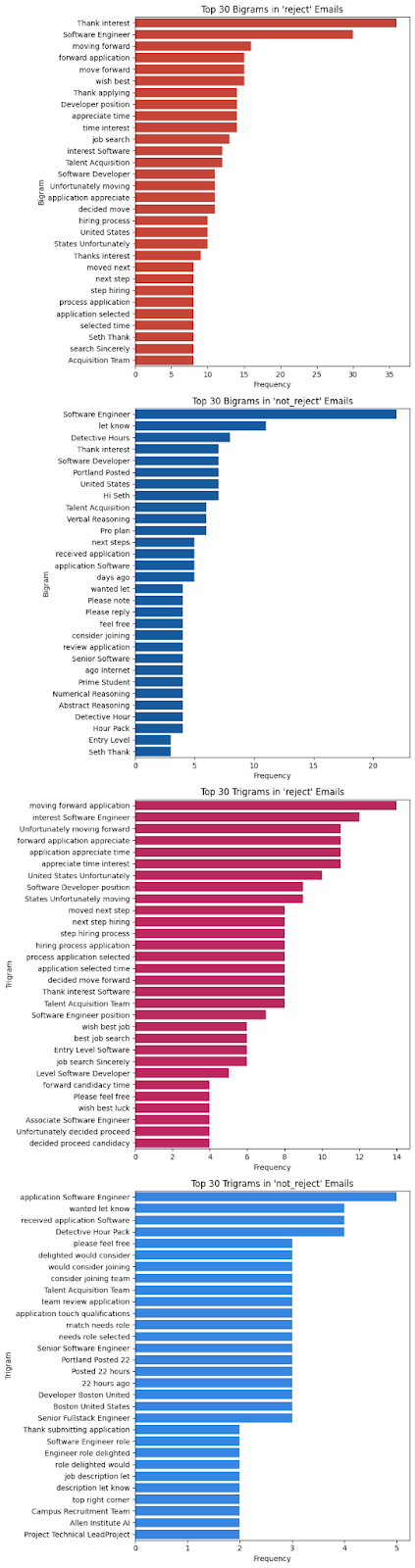
Now we're getting somewhere! By analysing bi- and trigrams, we can check for meaningful word collocations. In the context of job hunting, useful feedback might include phrases like 'lack of experience' or 'strong candidate.' However, as seen above, both rejection and non-rejection emails appear to be templated or automated responses.
So what about the overall sentiment of the emails? Using nltk's VADER sentiment analysis, we are able to establish sentiment intensity of each email group, where a higher score represents more positive vibes from the text:
Average Sentiment of Rejection Emails: 0.7727876923076923
Average Sentiment of Non-Rejection Emails: 0.711946875
Seems weird, right? This feels counterintuitive, particularly as rejection emails are rated as more positive than non-rejection. Given we have already established that reject emails are almost all going to be templates, this tells us that the vocabulary used is carefully chosen to avoid causing upset to the recipient. This means that phrases that we can see in the dataset such as 'thank you,' 'appreciate your time,' and 'qualifications are impressive' would be logged by VADER as skewing positive even though they can feature in a rejection email.
Let's look at this visually:
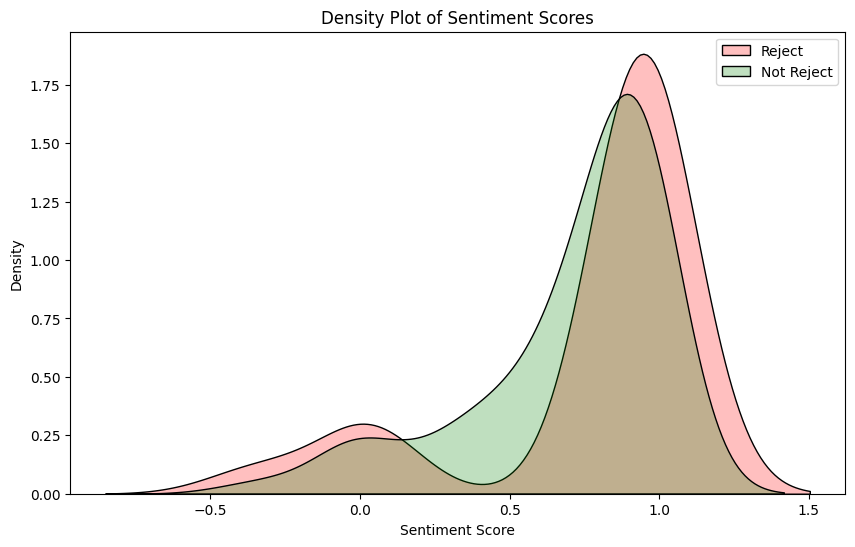
This density plot tells us rejection emails contain notably more positive words whilst the non-rejection emails contain a more even spread of positive words. The longer tail to the left of the x-axis also confirms that a number of the rejection emails do contain a negative slant. The green area in the middle of the density plot also reinforces the neutral nature of much of the contents of non-rejection emails.
But let's check how well our model can put words together by topic - in scientific terms this is known as Latent Dirichlet Allocation (LDA).
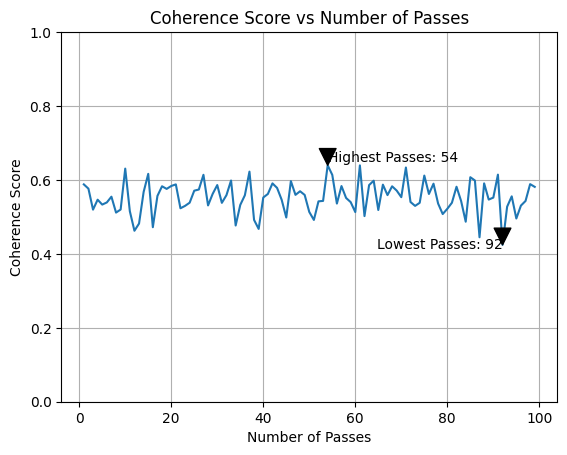
For 100 passes, 54 passes should be optimal to establish the most accurate topic models. (Don't worry - before doing this, a number of repeating words were added to the stopwords to reduce noise). The coherence score and topics across all the emails came out as follows:
Coherence Score: 0.5062862705042857
Topics for all emails:
0 ['Engineer', 'know', 'opportunities', 'let', 'please', 'future', 'development', 'role', 'may', 'best']
1 ['application', 'process', 'hiring', 'selected', 'get', 'applying', 'next', 'step', 'moved', 'Unfortunately']
2 ['application', 'Engineer', 'forward', 'Unfortunately', 'moving', 'Please', 'Developer', 'Regards', 'encourage', 'States']
3 ['Developer', 'best', 'employment', 'Java', 'positions', 'offer', 'open', 'United', 'States', 'opportunity']
4 ['decided', 'move', 'Seth', 'Thanks', 'Hi', 'another', 'get', 'Unfortunately', 'career', 'forward']
Key Takeaways 🥡
- The dataset showed little difference in basic vocabulary between successful and unsuccessful applications.
- Templated language suggests Polyniak's job hunt didn't progress beyond initial filtering, with many companies using templates for candidate communications.
- Sentiment analysis struggled to differentiate between genuine positivity and polite rejection language.
- Topic modelling showed rejection emails focus on future opportunities, while non-rejection emails highlight next steps.
- The dataset is limited (129 emails), affecting the effectiveness of the models due to small size and similar lexical richness across subsets.
- Suggested improvements include refining non-rejection emails into job-related and non-job-related categories, using models like BERTopic, and incorporating additional data points such as time and date for further analysis.
Key Features
- Sentiment Analysis using VADER
- Topic Modeling with LDA
- Text visualization with WordCloud